Have you ever had to wade through documents such as research papers, annual reports or Shakespeare's plays to quickly grasp the main ideas? Combining language models with tools such as Mermaid can increase productivity and save you research time.
Try using diagrams to visualise the information stored in documents. The charting tool Mermaid, powered by ChatGPT, can help you extract and process knowledge from texts, such as basic assumptions, relationships or syntactic information.
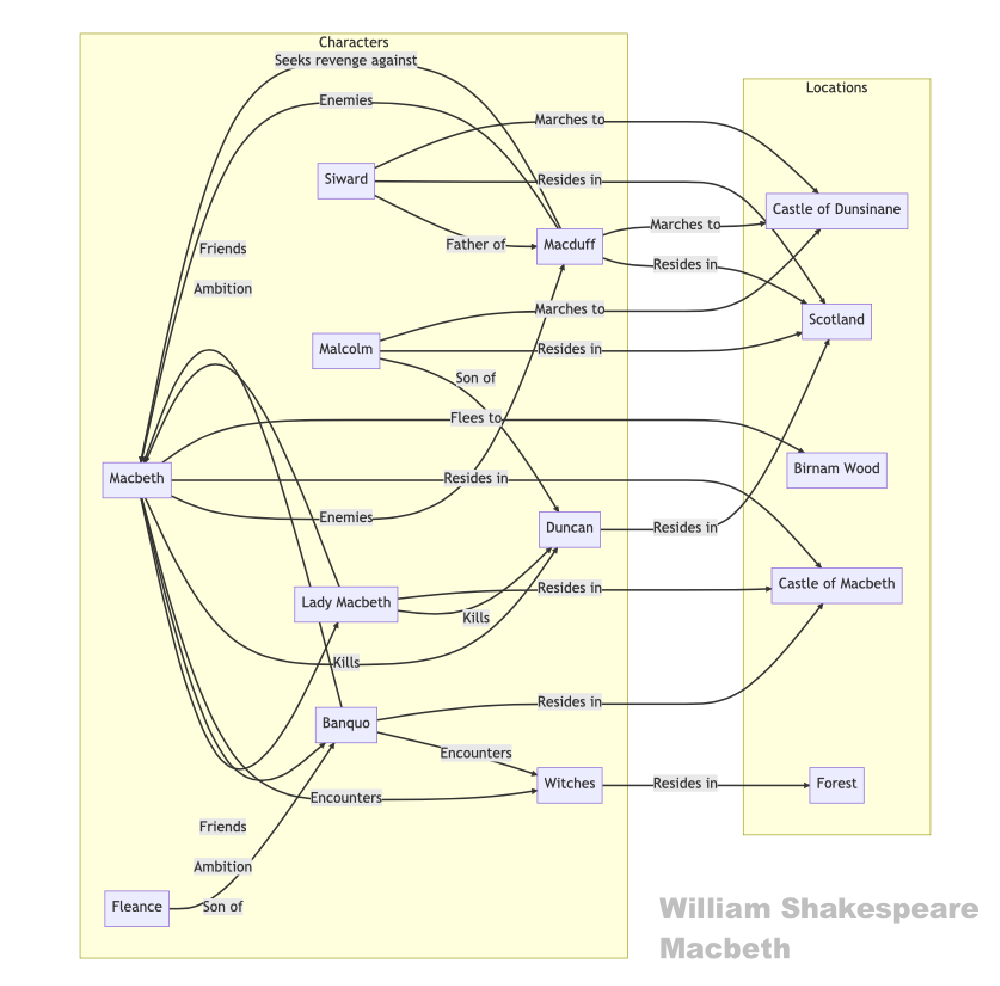 Textual analysis of Shakespeares Macbeth with ChatGPT and Mermaid (Copyright © CONNECTINGSCIENCE)
Textual analysis of Shakespeares Macbeth with ChatGPT and Mermaid (Copyright © CONNECTINGSCIENCE)
So what exactly is Mermaid? Mermaid describes itself as a JavaScript-based diagramming and charting tool. It provides a live editor and many charting features that ChatGPT can help you explore.
Let's get started: With Mermaid I was looking for a way to summarise content and create diagrams from it. I got some guidance from
David R Oliver's article on how to create Mermaid scripts with ChatGPT without needing in-depth knowledge of the script itself.
To get started, you will need to invest time in creating a comprehensive initial question. You can also start from scratch, but any wrong answer can lead your query in the wrong direction. The language model is able to analyse a code syntax, which is used as training data and acts as a template to go through any kind of text. The model can extract key information, weight it and help you create diagrams or illustrate relationships between concepts or entities. But as a researcher, student or business person, you need a solid understanding of the outcome you want to achieve. Because information can be inadequate and its reliability can be questioned.
The information generated by ChatGPT is based on statistical information calculated by a language model. In some cases, it misses relevant information, is not completely accurate and has other limitations - until now. An example: It has difficulty identifying the main characters in Romeo and Juliet without explicitly asking for it.
When you start a new ChatGPT session, it is important to think of it as a blank sheet of paper. Whatever you add to that paper will affect the outcome. By providing the initial content, you are setting the stage. You should therefore carefully consider the various steps you can take to ensure a valuable conversation in ChatGPT.
I will shortly demonstrate one approach by creating a diagram. Providing an initial Mermaid training script is the starting point and sets the scene for the outcome I am trying to achieve.
flowchart TB
c1-->a2
subgraph one
a1-->a2
end
subgraph two
b1-->b2
end
subgraph three
c1-->c2
end
ChatGPT processes the initial prompt and recreates the script with explanations. After this initial step you can easily add textual information and ask for deeper analysis. Let’s have a look on Shakespeares Romeo and Juliet:
Create a Mermaid script to visualize the main relationships and locations in Shakespeare's play "Romeo and Juliet."
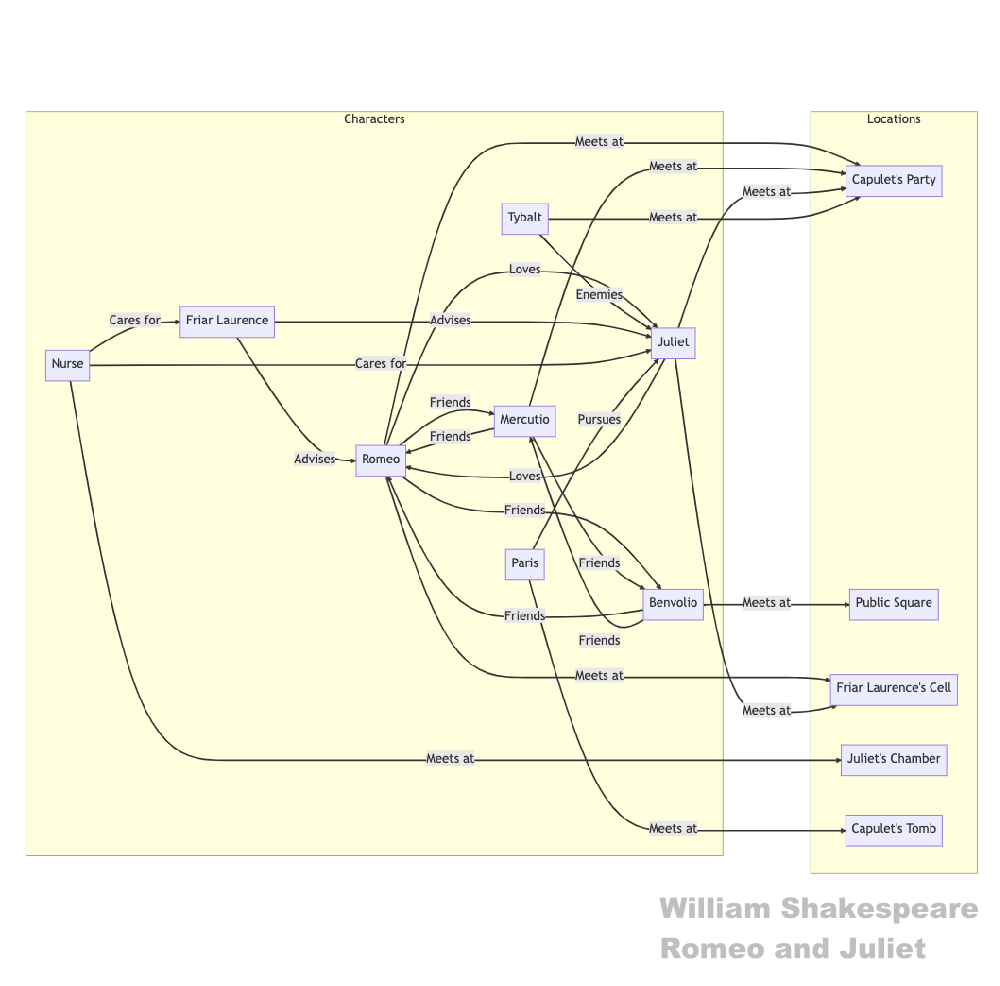 Textual analysis of Shakespeares Romeo and Juliet with ChatGPT and Mermaid (Copyright © CONNECTINGSCIENCE)
Textual analysis of Shakespeares Romeo and Juliet with ChatGPT and Mermaid (Copyright © CONNECTINGSCIENCE)
This ChatGPT prompt accesses textual information and analyzes it according to the assigned criteria. It is important to explicitly call out the involved components or relationship. By providing clear instructions, such as "mark the affiliation to the families Capulets and Montagues" ChatGPT will produce a extended Mermaid diagram that reflects the intended affiliation.
Adding, updating, and removing components and relationships within the diagram is needed to raise reliability in the provided data. The key to successfully making changes lies in providing unambiguous instructions to ChatGPT.
When dealing with such specific elements, precision becomes crucial. By being explicit and specific in your instructions, you can guide ChatGPT to accurately capture your intended diagram.
Here is the script for further research:
graph LR
subgraph Characters
R[Romeo]
J[Juliet]
M[Mercutio]
B[Benvolio]
T[Tybalt]
F[Friar Laurence]
N[Nurse]
P[Paris]
end
subgraph Locations
CP["Capulet's Party"]
PS["Public Square"]
FLC["Friar Laurence's Cell"]
JC["Juliet's Chamber"]
CT["Capulet's Tomb"]
end
R -- Loves --> J
J -- Loves --> R
R -- Friends --> M
R -- Friends --> B
B -- Friends --> R
B -- Friends --> M
M -- Friends --> R
M -- Friends --> B
T -- Enemies --> J
F -- Advises --> R
F -- Advises --> J
N -- Cares for --> J
N -- Cares for --> F
P -- Pursues --> J
R -- Meets at --> CP
M -- Meets at --> CP
J -- Meets at --> CP
T -- Meets at --> CP
B -- Meets at --> PS
R -- Meets at --> FLC
J -- Meets at --> FLC
N -- Meets at --> JC
P -- Meets at --> CT